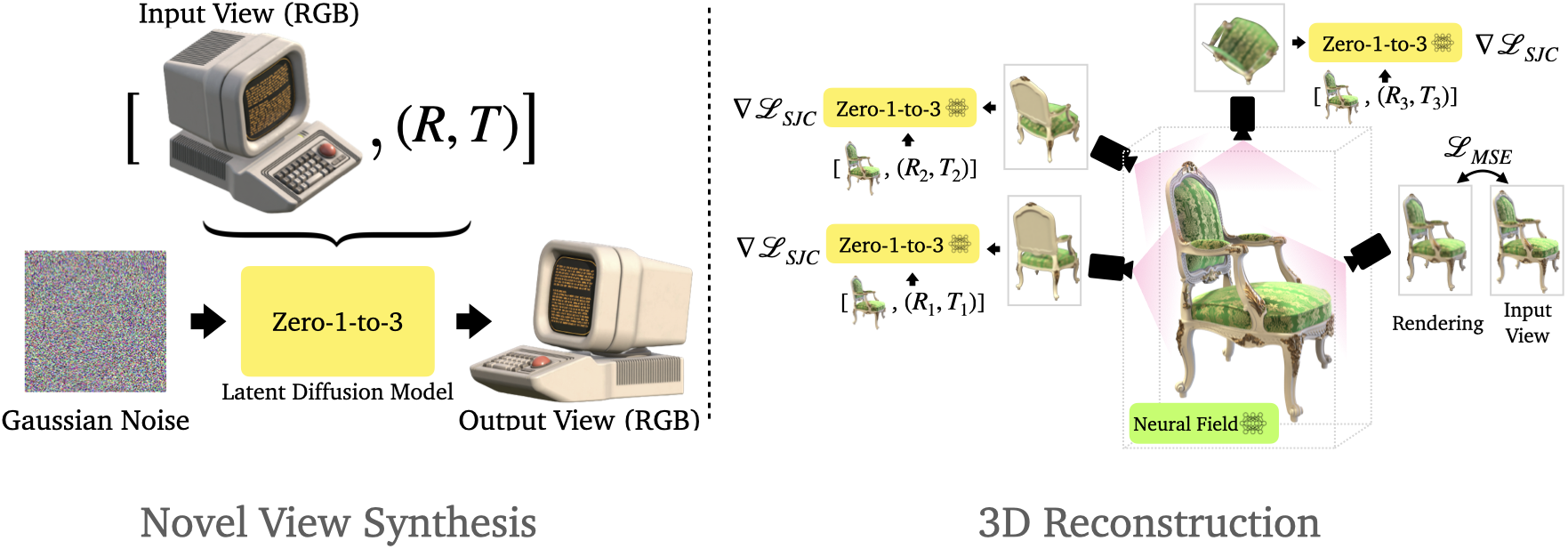
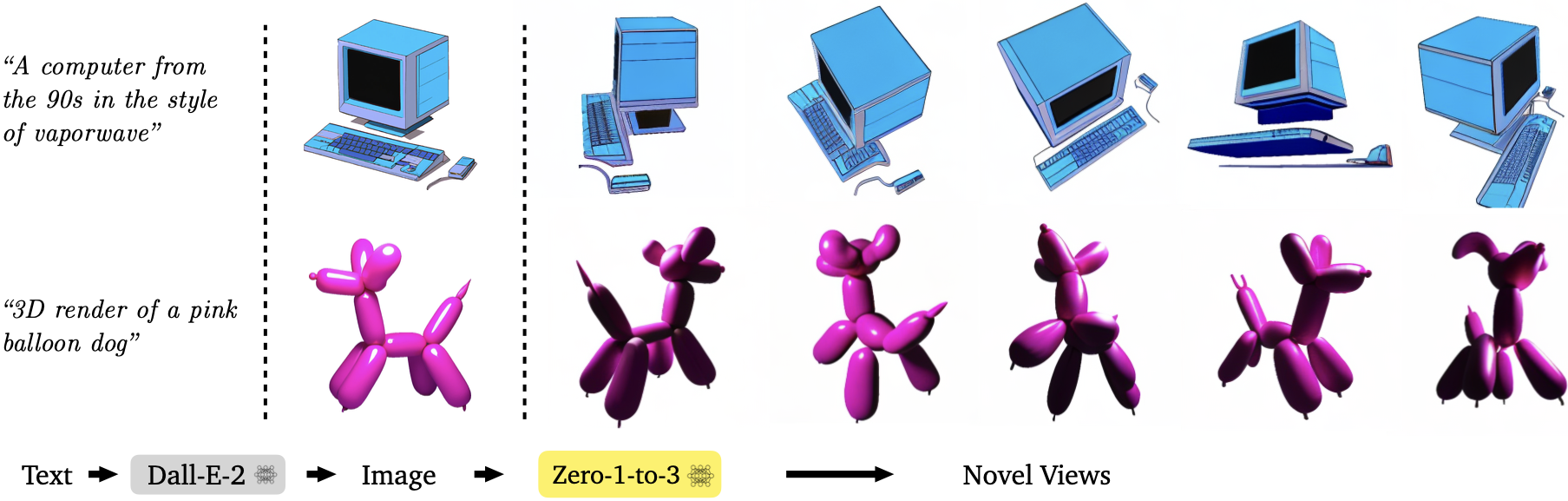
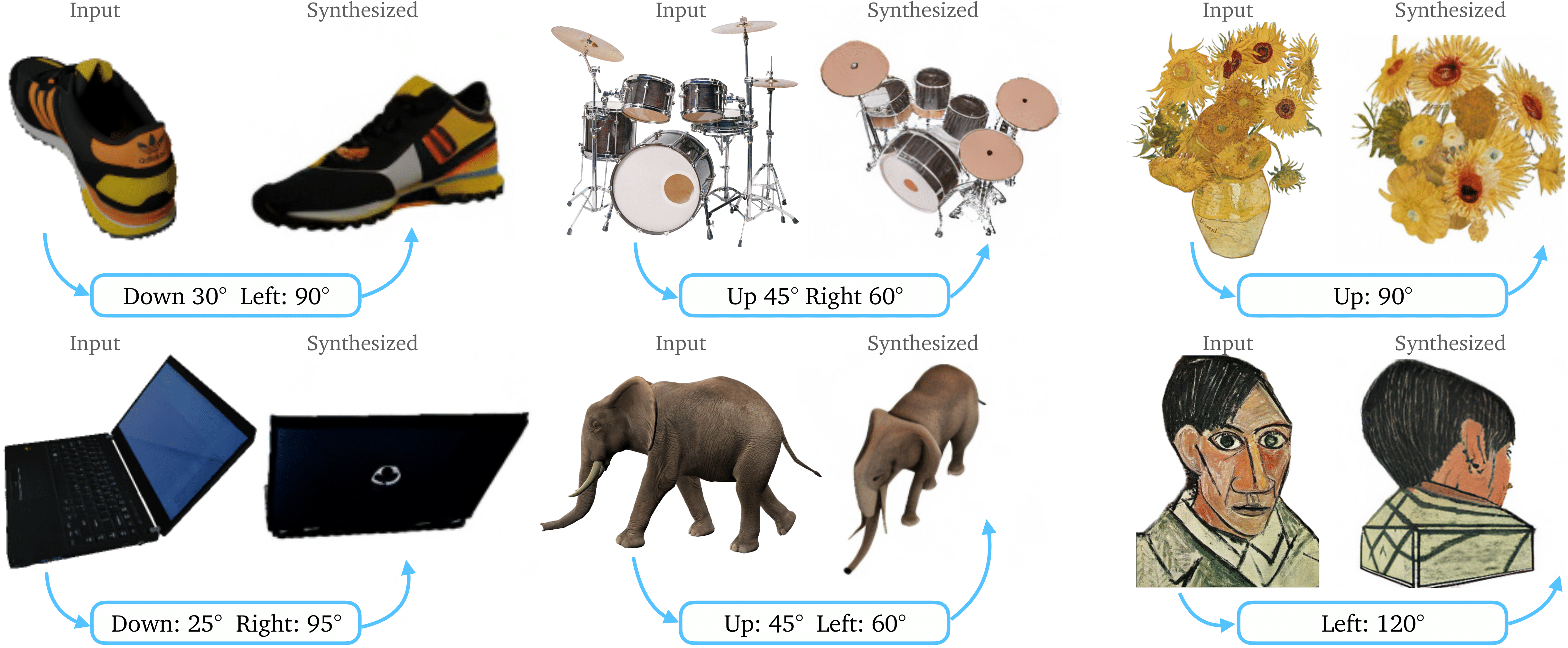
Zero-1-to-3: Zero-shot One Image to 3D Object
TL;DR: We learn to control the camera perspective in large-scale diffusion models, enabling zero-shot novel view synthesis and 3D reconstruction from a single image.




Arxiv
Code
Live Demo
Pretrained models